
Wired magazine recently contributed to the ongoing critique of traditional polling. Correctly, the magazine identified social media as the new frontier in gauging public sentiment – as opposed to random cold-calling of a tiny slice of the electorate. This is definitely the future.
But perhaps there is another layer of analytics still to add, if one is to apprehend the full picture of what voters and consumers are expressing on social media.
Wired quote Apoorv Agarwal, a computer scientist at Columbia University, when he states, “Machines are much better at doing sentiment analysis than humans now, especially on a large scale.”
Machines today are more sophisticated than ever. And it is certainly true they are vital for big data collection and understanding popular sentiment.
But social media analytics company, BrandsEye, believe that their approach to the process of understanding digital data adds a vital step in accurately mapping out what people are thinking and feeling, and where their loyalties and sentiments truly lie.
This additional step in the approach is something they call the Crowd – in which a team of online contributors process large quantities of unstructured data and apply human understanding to it. The defining characteristic of the BrandsEye Crowd is accuracy, with every data point subject to analysis by multiple contributors ensuring relevant sentiment based data is produced.
Through this approach and by integrating the information with intelligent software, companies can ensure the production of consistently accurate and reliable data.
To demonstrate the necessity of this component of garnering accurate insights, one can put the world’s most famous supercomputer, IBM’s Watson to the test.
Below is a tweet from the member of the public, who quotes a Trump tweet and then juxtaposes it with a data point from a poll, concluding her own tweet with the hashtag, #trumped.
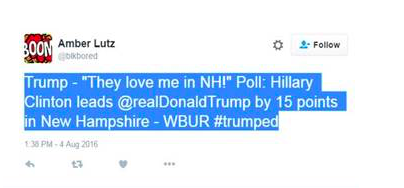
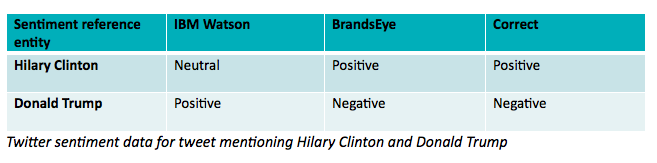
The problem is that when you insert such a tweet into Watson’s language processor, Alchemy Language, the supercomputer’s API (Application Programming Interface) misinterprets what does amount to a deceptively complex piece of political rhetoric.
Watson identifies the entities at hand – namely Trump and Clinton – but misattributes a positive sentiment to Trump, and a neutral sentiment to Clinton. The problem is Watson does not quite get the irony of the Twitter user’s Trump quote.
One comes across an even more basic problem when you use Google’s API to analyse the same piece of data. The Google alternative does not take the tweet and assign sentiments expressed to any identified entity – leaving any sentiment analysis adrift with no anchor in the real world.
In short, the Crowd integration may just provide an inside track in using the vast datascape of social media to assess sentiment and thus make both predictions and new strategic decisions.
Let’s take a look at one more tweet:
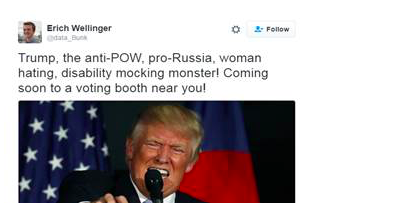
Here, Watson cannot understand the sarcasm of the statement. (AI experts have long noted humour and irony, which are innately human concepts, as the biggest obstacles in developing true AI.)

Technology is vitally important in politics, business, and data analysis, but it should never be forgotten that both politics and business remain, at their heart, human pursuits, which always consist of language, narrative, irony and emotion.
By integrating human analysis, and therefore adding local context and judgment to the process, one can cut through the clutter of unstructured data to produce a clear picture of what the public’s actual feelings are towards a brand or political candidate.
BrandsEye CEO, JP Kloppers, explains the process step by step.
“The first step is to hunt, gather, and store mentions based on predefined criteria across online, social, print and broadcast media.
“That data is then sent to the Crowd – that is, regular people, who can apply local knowledge and idiomatic and idiosyncratic understanding of the data so as to garner an accurate appraisal of the human sentiment contained within said data.
“The Crowd has been proven to evaluate these mentions at a success rate of up to 97%.”
This method would posit that it is a fallacy that machines are infallible and humans are not – because, unlike machines, humans can understand slang, the vernacular, and sarcasm.
The Crowd may make a few mistakes here and there – but given enough data, these errors can vanish into the negligible especially when one considers the current shortfall in machines understanding wordplay and paradox.
In a world in which emotion and sentiment still rule so much of our lives and choices, it is of course quite logical that we still need human understanding to perfect the data analysis process even when using the world’s most impressive and advanced systems.
The effectiveness of the Crowd shows just why human involvement in the sorting of big data is an ongoing necessity – especially in the highly sophisticated discourse of social media.
In what is shaping to be a pivotal, and entirely unprecedented, American election season, this effectiveness might just be critical as political parties and media players seek to stay ahead of the information curve.
Chris Waldburger is a freelance analyst and writer, whose work can be found at chriswaldburger.com












{kind=link}